How We Reduced the Impact of Zombie Clients
Every night, right around midnight (mainly UTC), a horde of zombies wakes up and clamors for … digital certificates!
The zombies in question are abandoned or misconfigured Internet servers and ACME clients that have been set to request certificates from Let’s Encrypt. As our certificates last for at most 90 days, these zombie clients’ software knows that their certificates are out-of-date and need to be replaced. What they don’t realize is that their quest for new certificates is doomed! These devices are cursed to seek certificates again and again, never receiving them.
But they do use up a lot of certificate authority resources in the process.
The Zombie Client Problem
Unlike a human being, software doesn’t give up in frustration, or try to modify its approach, when it repeatedly fails at the same task. Our emphasis on automation means that the vast majority of Let’s Encrypt certificate renewals are performed by automated software. This is great when those renewals succeed, but it also means that forgotten clients and devices can continue requesting renewals unsuccessfully for months, or even years.
How might that happen? Most often, it happens when a device no longer has a domain name pointed to it. The device itself doesn’t know that this has changed, so it treats renewal failures as transient even though they are actually permanent. For instance:
- An organization may have allowed a domain name registration to lapse because it is no longer needed, but its servers are still configured to request certs for it.
- Or, a home user stopped using a particular dynamic-DNS domain with a network-attached storage device, but is still using that device at home. The device doesn’t realize that the user no longer expects to use the name, so it keeps requesting certs for it.
- Or, a web hosting or CDN customer migrated to a different service provider, but never informed the old service provider. The old service provider’s servers keep requesting certs unsuccessfully. If the customer was in a free service tier, there might not be invoices or charges reminding the customer to cancel the service.
- Or any number of other, subtler changes in a subscriber’s infrastructure, such as changing a firewall rule or some webserver configuration.
At the scale of Let’s Encrypt, which now covers hundreds of millions of names, scenarios like these have become common, and their impact has become substantial. In 2024, we noticed that about half of all certificate requests to the Let’s Encrypt ACME API came from about a million accounts that never successfully complete any validations. Many of these had completed validations and issued certificates sometime in the past, but nowadays every single one of their validation attempts fails, and they show no signs that this will change anytime soon.
Unfortunately, trying to validate those futile requests still uses resources. Our CA software has to generate challenges, reach out and attempt to validate them over the Internet, detect and report failures, and record all of the associated information in our databases and audit logs. And over time, we’ve seen more and more recurring failures: accounts that always fail their issuance requests have been growing at around 18% per year.
In January, we mentioned that we had been addressing the zombie client problem through our rate limit system. This post provides more detail on that progress.
Our Rate Limit Philosophy
If you’ve used Let’s Encrypt as a subscriber, you may have run into one of our rate limits at some point, maybe during your initial setup process. We have eight different kinds of rate limits in place now; as our January post describes, they’ve become more algorithmically sophisticated and grown to address a wider range of problems. A key principle for Let’s Encrypt is that our rate limiting is not a punishment. We don’t think of rate limits as a way of retaliating against a client for misbehavior. Rate limits are simply a tool to maximize the efficient use of our limited resources and prevent people and programs from using up those resources for no constructive purpose.
We’ve consistently tried to design our rate limit mechanisms in line with that philosophy. So if a misconfiguration or misunderstanding has caused excessive requests in the past, we’re still happy to welcome the user in question back and start issuing them certificates again—once the problem has been addressed. We want the rate limits to put a brake on wasteful use of our systems, but not to frustrate users who are actively trying to make Let’s Encrypt work for them.
In addition, we’ve always implemented our rate limits to err on the side of permissiveness. For example, if the Redis instances where rate limits are tracked have an outage or lose data, the system is designed to permit more issuance rather than less issuance as a result.
We wanted to create additional limits that would target zombie clients, but in a correspondingly non-punitive way that would avoid any disruption to valid issuance, and welcome subscribers back quickly if they happened to notice and fix a long-time problem with their setups.
Our Zombie-Related Rate Limits and Their Impact
In planning a new zombie-specific response, we decided on a “pausing” approach, which can temporarily limit an account’s ability to proceed with certificate requests. The core idea is that, if a particular account consistently fails to complete validation for a particular hostname, we’ll pause that account-hostname pair. The pause means that any new order requests from that account for that hostname will be rejected immediately, before we get to the resource-intensive validation phase.
This approach is more finely targeted than pausing an entire account. Pausing account-hostname pairs means that your ability to issue certs for a specific name could be paused due to repeated failures, but you can still get all of your other certs like normal. So a large hosting provider doesn’t have to fear that its certificate issuance on behalf of one customer will be affected by renewal failures related to a problem with a different customer’s domain name. The account-specificity of the pause, in turn, means that validation failures from one subscriber or device won’t prevent a different subscriber or device from attempting to validate the same name, as long as the devices in question don’t share a single Let’s Encrypt account.
In September 2024, we began applying our zombie rate limits manually by pausing about 21,000 of the most recurrently-failing account-hostname pairs, those which were consistently repeating the same failed requests many times per day, every day. After implementing that first round of pauses, we immediately saw a significant impact on our failed request rates. As we announced at that time, we also began using a formula to automatically pause other zombie client account-hostname pairs from December 2024 onward. The associated new rate limit is called “Consecutive Authorization Failures per Hostname Per Account” (and is independent of the existing “Authorization Failures per Hostname Per Account” limit, which resets every hour).
This formula relates to the frequency of successive failed issuance requests for the same domain name by the same Let’s Encrypt account. It applies only to failures that happen again and again, with no successful issuances at all in between: a single successful validation immediately resets the rate limit all the way to zero. Like all of our rate limits, this is not a punitive measure but is simply intended to reduce the waste of resources. So, we decided to set the thresholds rather high in the expectation that we would catch only the most disruptive zombie clients, and ultimately only those clients that were extremely unlikely to succeed in the future based on their substantial history of failed requests. We don’t hurry to block requesters as zombies: according to our current formula, client software following the default established by EFF’s Certbot (two renewal attempts per day) would be paused as a zombie only after about ten years of constant failures. More aggressive failed issuance attempts will get a client paused sooner, but clients will generally have to fail hundreds or thousands of attempts in a row before they are paused.
Most subscribers using mainstream client applications with default configurations will never encounter this rate limit, even if they forget to deactivate renewal attempts for domains that are no longer pointed at their servers. As described below, our current limit is already providing noticeable benefits with minimal disruption, and we’re likely to tighten it a bit in the near future, so it will trigger after somewhat fewer consecutive failures.
Self-Service Unpausing
A key feature in our zombie issuance pausing mechanism is self-service unpausing. Whenever an account-hostname pair is paused, any new certificate requests for that hostname submitted by that account are immediately rejected. But this means that the “one successful validation immediately resets the rate limit counter” feature can no longer come into effect: once they’re paused, they can’t even attempt validation anymore.
So every rejection comes with an error message explaining what has happened and a custom link that can be used to immediately unpause that account-hostname pair and remove any other pauses on the same account at the same time. The point of this is that subscribers who notice at some point that issuance is failing and want to intervene to get it working again have a straightforward option to let Let’s Encrypt know that they’re aware of the recurring failures and are still planning to use a particular account. As soon as subscribers notify us via the self-service link, they’ll be able to issue certificates again.
Currently, the user interface for an affected subscriber looks like this:
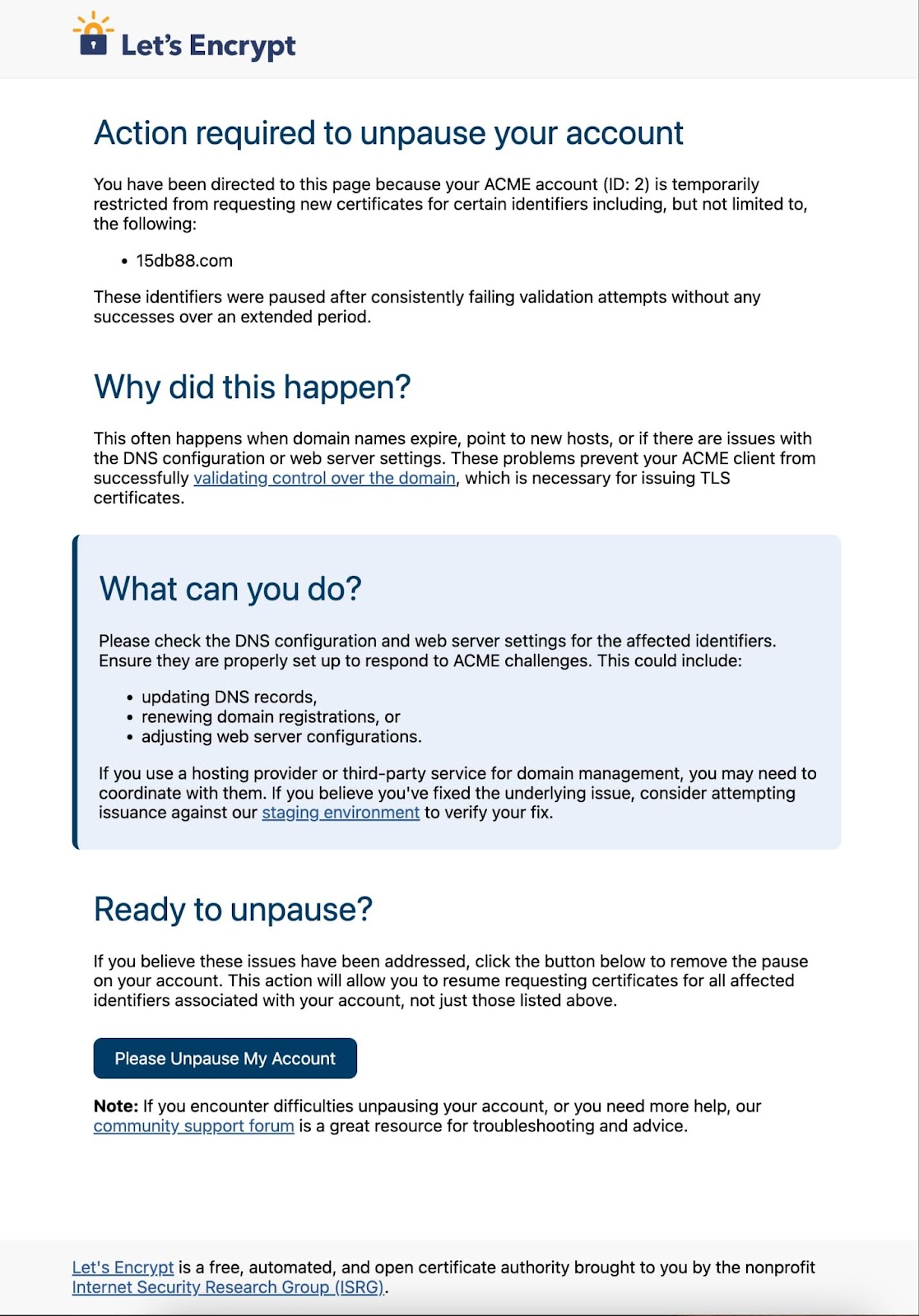
This link would be provided via an ACME error message in response to any request that was blocked due to a paused account-hostname pair.
As it’s turned out, the unpause option shown above has only been used by about 3% of affected accounts! This goes to show that most of the zombies we’ve paused were, in fact, well and truly forgotten about.
However, the unpause feature is there for whenever it’s needed, and there may be cases when it will become more important. A very large integration could trigger the zombie-related rate limits if a newly-introduced software bug causes what looks like a very high volume of zombie requests in a very short time. In that case, once that bug has been noticed and fixed, an integrator may need to unpause its issuance on behalf of lots of customers at once. Our unpause feature permits unpausing 50,000 domain names on a single account at a time, so even the largest integrators can get themselves unpaused expeditiously in this situation.
Conclusion
We’ve been very happy with the results of our zombie mitigation measures, and, as far as we can tell, there’s been almost no impact for subscribers! Our statistics indicate that we’ve managed to reduce the load on our infrastructure while causing no detectable harm or inconvenience to subscribers’ valid issuance requests.
Since implementing the manual pauses in September and the automated pauses in December, we’ve seen:
- Over 100,000 account-hostname pairs have been paused for excessive failures.
- We received zero (!) associated complaints or support requests.
- About 3,200 people manually unpaused issuance.
- Failed certificate orders fell by about 30% so far, and should continue to fall over time as we fine-tune the rate limit formula and catch more zombie clients.
The new rate limit and the self-service unpause system are also ready to deal with circumstances that might produce more zombie clients in the future. For instance, we’ve announced that we’re going to be discontinuing renewal reminder emails soon. If some subscribers overlook failed renewals in the future, we might see more paused clients that result from unintentional renewal failures. We think taking advantage of the existing self-service unpause feature will be straightforward in that case. But it’s much better to notice problems and get them fixed up front, so please remember to set up your own monitoring to avoid unnoticed renewal failures in the future.
If you’re a subscriber who’s had occasion to use the self-service unpause feature, we’d love your feedback on the Community Forum about your experience using the feature and the circumstances that surrounded your account’s getting paused.
Also, if you’re a Let’s Encrypt client developer, please remember to make renewal requests at a random time (not precisely at midnight) so that the load on our infrastructure is smoothed out. You can also reduce the impact of zombie renewals by repeating failed requests somewhat less frequently over time (a “back-off” strategy), especially if the failure reason makes it look like a domain name may no longer be in use at all.