Nurturing Continued Growth of Our Oak CT Log
Let’s Encrypt has been running a Certificate Transparency (CT) log since 2019 as part of our commitment to keeping the Web PKI ecosystem healthy. CT logs have become important infrastructure for an encrypted Web 1, but have a well-deserved reputation for being difficult to operate at high levels of trust: Only 6 organizations run logs that are currently considered to be “qualified.” 2
Our Oak log is the only qualified CT log that runs on an entirely open source stack 3. In the interest of lowering the barrier for other organizations to join the CT ecosystem, we want to cover a few recent changes to Oak that might be helpful to anyone else planning to launch a log based on Google’s Trillian backed by MariaDB:
-
The disk I/O workload of Trillian atop MariaDB is easily mediated by front-end rate limits, and
-
It’s worth the complexity to split each new annual CT log into its own Trillian/MariaDB stack.
This post will update some of the information from the previous post How Let’s Encrypt Runs CT Logs.
Growing Oak While Staying Open Source
Oak runs on a free and open source stack: Google’s Trillian data store, backed by MariaDB, running at Amazon Web Services (AWS) via Amazon’s Relational Database Service (RDS). To our knowledge, Oak is the only trusted CT log without closed-source components 3.
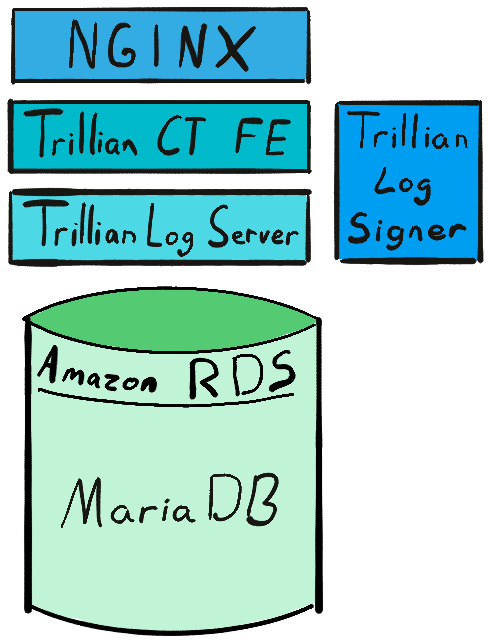
Open Source Stack
Other operators of Trillian have opted to use different databases which segment data differently, but the provided MySQL-compatible datastore has successfully kept up with Let’s Encrypt’s CT log volume (currently above 400 GB per month). The story for scaling Oak atop MariaDB is quite typical for any relational database, though the performance requirements are stringent.
Keeping Oak Qualified
The policies that Certificate Transparency Log operators follow require there to be no significant downtime, in addition to the more absolute and difficult requirement that the logs themselves make no mistakes: Given the append-only nature of Certificate Transparency, seemingly minor data corruption prompts permanent disqualification of the log 4. To minimize the impacts of corruption, as well as for scalability reasons, it’s become normal for CT logs to distribute the certificates they contain in different, smaller individual CT logs, called shards.
Splitting Many Years Of Data Among Many Trees
The Let’s Encrypt Oak CT log is actually made up of many individual CT log shards each named after a period of time: Oak 2020 contains certificates which expired in 2020; Oak 2022 contains certificates which expire in 2022. For ease of reference, we refer to these as “temporal log shards,” though in truth each is an individual CT log sharing the Oak family name.
It is straightforward to configure a single Trillian installation to support multiple CT log shards. Each log shard is allocated storage within the backing database, and the Trillian Log Server can then service requests for all configured logs.
The Trillian database schema is quite compact and easy to understand:
-
Each configured log gets a Tree ID, with metadata in several tables.
-
All log entries – certificates in our case – get a row in LeafData.
-
Entries that haven’t been sequenced yet get a row in the table Unsequenced, which is normally kept empty by the Trillian Log Signer service.
-
Once sequenced, entries are removed from the Unsequenced table and added as a row in SequencedLeafData.
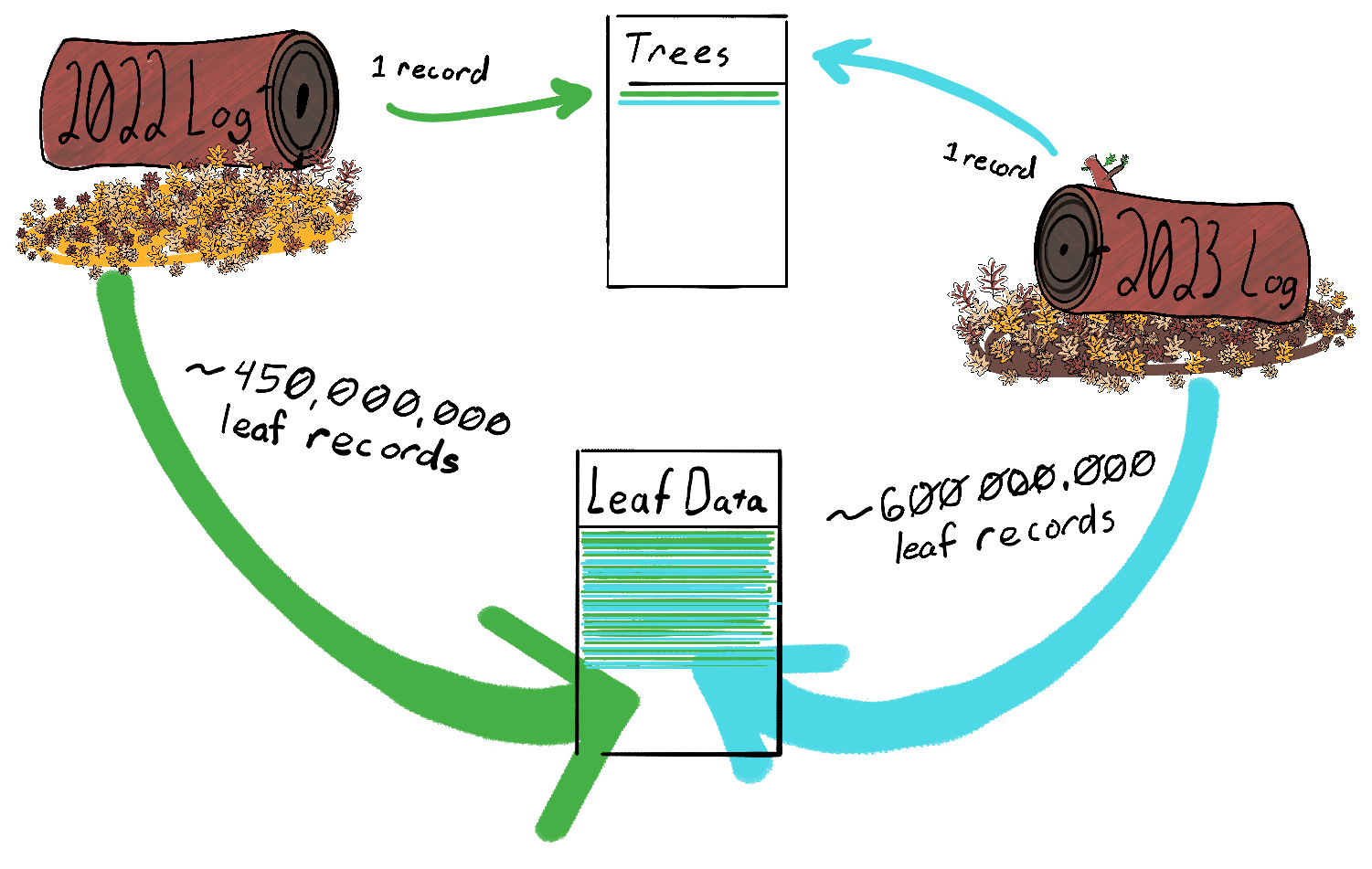
Database Layout
In a nutshell: No matter how many different certificate transparency trees and subtrees you set up for a given copy of Trillian, all of them will store the lion’s share of their data, particularly the DER-encoded certificates themselves, interwoven into the one LeafData table. Since Trillian Log Server can only be configured with a single MySQL connection URI, limiting it to a single database, that single table can get quite big.
For Oak, the database currently grows at a rate of about 400 GB per month; that rate is ever-increasing as the use of TLS grows and more Certificate Authorities submit their certificates to our logs.
Amazon RDS Size Limitations
In March 2021 we discovered that Amazon RDS has a 16TB limit per tablespace when RDS is configured to use one file-per-table, as we were doing for all of our CT log shards. Luckily, we reached this limit first in our testing environment, the Testflume log.
Part of Testflume’s purpose was to grow ahead of the production logs in total size, as well as test growth with more aggressive configuration options than the production Oak log had, and in these ways it was highly successful.
Revisiting Database Design
In our blog post, How Let’s Encrypt Runs CT Logs, we wrote that each year we planned “to freeze the previous year’s shard and move it to a less expensive serving infrastructure, reclaiming its storage for our live shards.” However, that is not practical while continuing to serve traffic from the same database instance. Deleting terabytes of rows from an InnoDB table that is in-use is not feasible. Trillian’s MySQL-compatible storage backend agrees: as implemented, Trillian’s built-in Tree Deletion mechanism marks a tree as “soft deleted,” and leaves the removal of data from the LeafData table (and others) as an exercise for the administrator.
Since Trillian’s MySQL-compatible backend does not support splitting the LeafData among multiple tables by itself, and since deleting stale data from those tables yields slow performance across the whole database server, to continue to scale the Oak CT log we have to instead prune out the prior seasons’ data another way.
Single RDS Instance with Distinct Schema per Log Shard
We considered adding new database schemas to our existing MariaDB-backed Amazon RDS instance. In this design, we would run a Trillian CT Front-End (CTFE) instance per temporal log shard, each pointing to individual Trillian Log Server and Log Signer instances, which themselves point to a specific temporally-identified database schema name and tablespace. This is cost-effective, and it gives us ample room to avoid the 16 TB limit.

Distinct Schema per Log Shard in a Single Database
However, if heavy maintenance is required on any part of the underlying database, it would affect every log shard contained within. In particular, we know from using MariaDB with InnoDB inside the Let’s Encrypt CA infrastructure that truncating and deleting a multi-terabyte table causes performance issues for the whole database while the operation runs. Inside the CA infrastructure we mitigate that performance issue by deleting table data only on database replicas; this is more complicated in a more hands-off managed hosting environment like RDS.
Since we wish to clear out old data regularly as a matter of data hygiene, and the performance requirements for a CT log are strict, this option wasn’t feasible.
Distinct RDS Instance per Log Shard
While it increases the number of managed system components, it is much cleaner to give each temporal log shard its own database instance. Like the Distinct Schema per Log Shard model, we now run Trillian CTFE, Log Server, and Log Signer instances for each temporal log shard. However, each log shard gets its own RDS instance for the active life of the log 5. At log shutdown, the RDS instance is simply deprovisioned.

Using Distinct Databases Per Log
With the original specifications for the Oak log, this would require allocating a significant amount of data I/O resources. However, years of experience running the Testflume log showed that Trillian in AWS did not require the highest possible disk performance.
Tuning IOPS
We launched Oak using the highest performance AWS Elastic Block Storage available at the time: Provisioned IOPS SSDs (type io1). Because of the strict performance requirements on CT logs, we worried that without the best possible performance for disk I/O that latency issues might crop up that could lead to disqualification. As we called out in our blog post How Let’s Encrypt Runs CT Logs, we hoped that we could use a simpler storage type in the future.
To test that, we used General Purpose SSD storage type (type gp2) for our testing CT log, Testflume, and obtained nominal results over the lifespan of the log. In practice higher performance was unnecessary because Trillian makes good use of database indices. Downloading the whole log tree from the first leaf entry is the most significant demand of disk I/O, and that manner of operation is easily managed via rate limits at the load balancer layer.
Our 2022 and 2023 Oak shards now use type gp2 storage and are performing well.
Synergistically, the earlier change to run a distinct RDS instance for each temporal log shard has also further reduced Trillian’s I/O load: A larger percentage of the trimmed-down data fits in MariaDB’s in-memory buffer pool.
More Future Improvements
It’s clear that CT logs will continue to accelerate their rate of growth. Eventually, if we remain on this architecture, even a single year’s CT log will exceed the 16 TB table size limit. In advance of that, we’ll have to take further actions. Some of those might be:
-
Change our temporal log sharding strategy to shorter-than-year intervals, perhaps every 3 or 6 months.
-
Reduce the absolute storage requirements for Trillian’s MySQL-compatible storage backend by de-duplicating intermediate certificates.
-
Contribute a patch to add table sharding to Trillian’s MySQL-compatible storage backend.
-
Change storage backends entirely, perhaps to a sharding-aware middleware, or another more horizontally-scalable open-source system.
We’ve also uprooted our current Testflume CT log and brought online a replacement which we’ve named Sapling. As before, this test-only log will evaluate more aggressive configurations that might bear fruit in the future.
As Always, Scaling Data Is The Hard Part
Though the performance requirements for CT logs are strict, the bulk of the scalability difficulty has to do with the large amount of data and the high and ever-increasing rate of growth; this is the way of relational databases. Horizontal scaling continues to be the solution, and is straightforward to apply to the open source Trillian and MariaDB stack.
Supporting Let’s Encrypt
As a nonprofit project, 100% of our funding comes from contributions from our community of users and supporters. We depend on their support in order to provide our services for the public benefit. If your company or organization would like to sponsor Let’s Encrypt please email us at sponsor@letsencrypt.org. If you can support us with a donation, we ask that you make an individual contribution.
-
Chrome and Safari check that certificates include evidence that certificates were submitted to CT logs. If a certificate is lacking that evidence, it won’t be trusted. https://certificate.transparency.dev/useragents/ ↩︎
-
As of publication, these organizations have logs Google Chrome considers qualified for Certificate Authorities to embed their signed timestamps: Cloudflare, DigiCert, Google, Let’s Encrypt, Sectigo, and TrustAsia. https://ct.cloudflare.com/logs and https://twitter.com/__agwa/status/1527407151660122114 ↩︎
-
DigiCert’s Yeti CT log deployment at AWS uses a custom Apache Cassandra backend; Oak is the only production log using the Trillian project’s MySQL-compatible backend. SSLMate maintains a list of known log software at https://sslmate.com/labs/ct_ecosystem/ecosystem.html ↩︎
-
In the recent past, a cosmic ray event led to the disqualification of a CT log. Andrew Ayer has a good discussion of this in his post “How Certificate Transparency Logs Fail and Why It’s OK” https://www.agwa.name/blog/post/how_ct_logs_fail, which references the discovery on the ct-policy list https://groups.google.com/a/chromium.org/g/ct-policy/c/PCkKU357M2Q/m/xbxgEXWbAQAJ\ ↩︎
-
Logs remain online for a period after they stop accepting new entries to give a grace period for mirrors and archive activity. ↩︎