The Next Gen Database Servers Powering Let's Encrypt
Let’s Encrypt helps to protect a huge portion of the Web by providing TLS certificates to more than 235 million websites. A database is at the heart of how Let’s Encrypt manages certificate issuance. If this database isn’t performing well enough, it can cause API errors and timeouts for our subscribers. Database performance is the single most critical factor in our ability to scale while meeting service level objectives. In late 2020, we upgraded our database servers and we’ve been very happy with the results.
What exactly are we doing with these servers?
Our CA software, Boulder, uses MySQL-style schemas and queries to manage subscriber accounts and the entire certificate issuance process. It’s designed to work with a single MySQL, MariaDB, or Percona database. We currently use MariaDB, with the InnoDB database engine.
We run the CA against a single database in order to minimize complexity. Minimizing complexity is good for security, reliability, and reducing maintenance burden. We have a number of replicas of the database active at any given time, and we direct some read operations to replica database servers to reduce load on the primary.
One consequence of this design is that our database machines need to be pretty powerful. Eventually we may need to shard or break the single database into multiple databases, but hardware advancements have allowed us to avoid that so far.
Hardware Specifications
The previous generation of database hardware was powerful but it was regularly being pushed to its limits. For the next generation, we wanted to more than double almost every performance metric in the same 2U form factor. In order to pull that off, we needed AMD EPYC chips and Dell’s PowerEdge R7525 was ideal. Here are the specifications:
| Previous Generation | Next Generation | |
| CPU | 2x Intel Xeon E5-2650 Total 24 cores / 48 threads |
2x AMD EPYC 7542 Total 64 cores / 128 threads |
| Memory | 1TB 2400MT/s | 2TB 3200MT/s |
| Storage | 24x 3.8TB Samsung PM883 SATA SSD 560/540 MB/s read/write |
24x 6.4TB Intel P4610 NVMe SSD 3200/3200 MB/s read/write |

By going with AMD EPYC, we were able to get 64 physical CPU cores while keeping clock speeds high: 2.9GHz base with 3.4GHz boost. More importantly, EPYC provides 128 PCIe v4.0 lanes, which allows us to put 24 NVMe drives in a single machine. NVMe is incredibly fast (~5.7x faster than the SATA SSDs in our previous-gen database servers) because it uses PCIe instead of SATA. However, PCIe lanes are typically very limited: modern consumer chips typically have only 16 lanes, and Intel’s Xeon chips have 48. By providing 128 PCI lanes per chip (v4.0, no less), AMD EPYC has made it possible to pack large numbers of NVMe drives into a single machine. We’ll talk more about NVMe later.
Performance Impact
We’ll start by looking at our median time to process a request because it best reflects subscribers’ experience. Before the upgrade, we turned around the median API request in ~90 ms. The upgrade decimated that metric to ~9 ms!

We can clearly see how our old CPUs were reaching their limit. In the week before we upgraded our primary database server, its CPU usage (from /proc/stat) averaged over 90%:
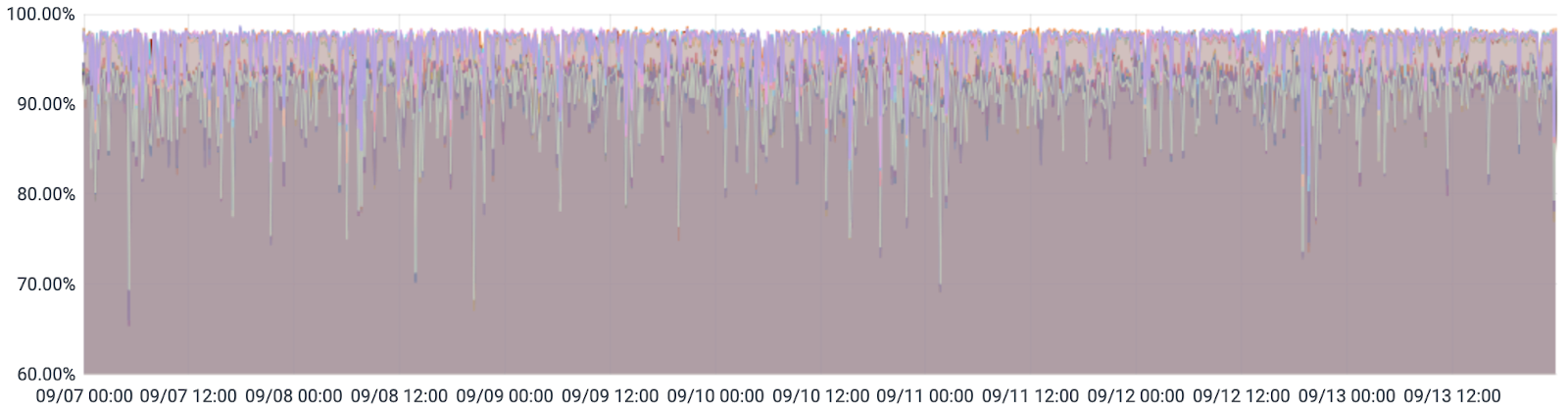
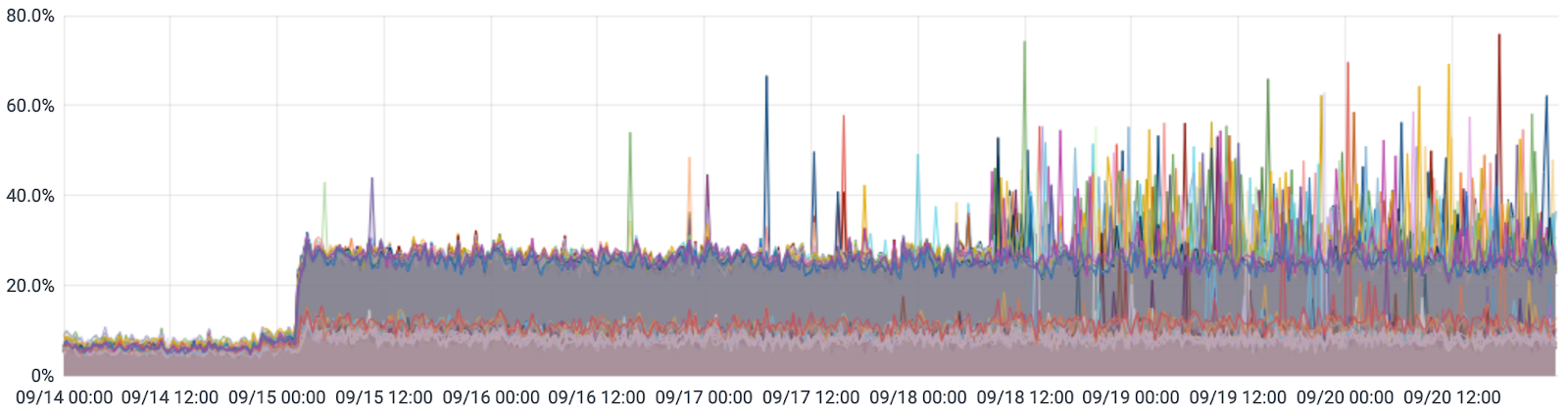
The new AMD EPYC CPUs sit at about 25%. You can see in this graph where we promoted the new database server from replica (read-only) to primary (read/write) on September 15.
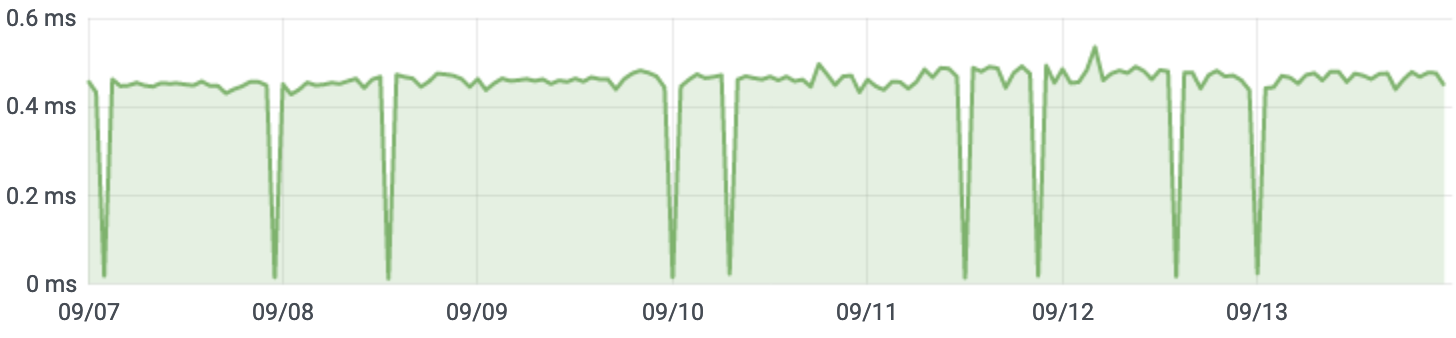
The upgrade greatly reduced our overall database latency. The average query response time (from INFORMATION_SCHEMA) used to be ~0.45ms.
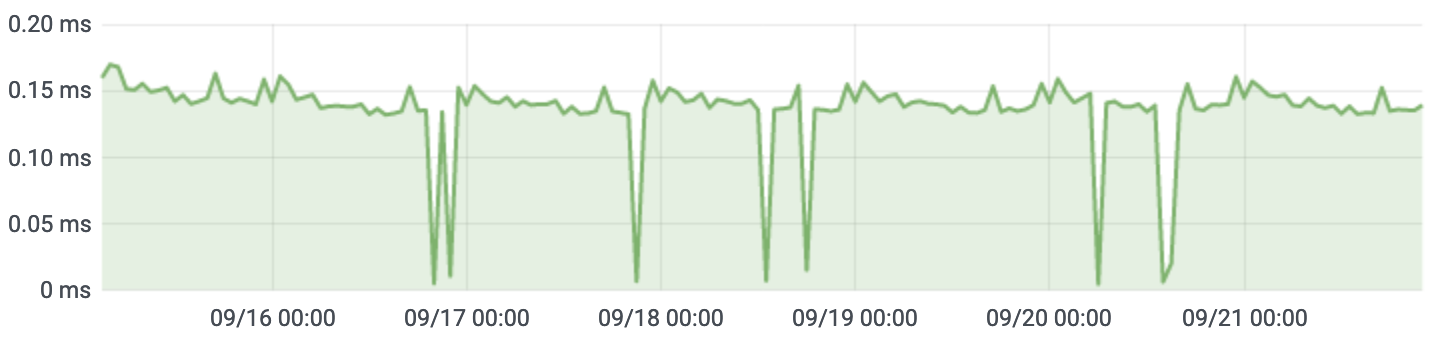
Queries now average three times faster, about 0.15ms.
OpenZFS and NVMe
NVMe drives are becoming increasingly popular because of their incredible performance. Up until recently, though, it was nearly impossible to get many of them in a single machine because NVMe uses PCIe lanes. Those were very limited: Intel’s Xeon processors come with just 48 PCIe v3 lanes, and a number of those are used up by the chipset and add-on cards such as network adapters and GPUs. You can’t fit many NVMe drives in the remaining lanes.
AMD’s latest generation of EPYC processors come with 128 PCIe lanes - more than double what Intel offers - and they’re PCIe v4! This is enough to pack a 2U server full of NVMe drives (24 in our case).
Once you have a server full of NVMe drives, you have to decide how to manage them. Our previous generation of database servers used hardware RAID in a RAID-10 configuration, but there is no effective hardware RAID for NVMe, so we needed another solution. One option was software RAID (Linux mdraid), but we got several recommendations for OpenZFS and decided to give it a shot. We’ve been very happy with it!
There wasn’t a lot of information out there about how best to set up and optimize OpenZFS for a pool of NVMe drives and a database workload, so we want to share what we learned. You can find detailed information about our setup in this GitHub repository.
Conclusion
This database upgrade was necessary as more people rely on Let’s Encrypt for the security and privacy that TLS/SSL provides. The equipment is quite expensive and it was a sizable undertaking for our SRE team to plan and execute the transition, but we gained a lot through the process.
Support Let’s Encrypt
We depend on contributions from our supporters in order to provide our services. If your company or organization would like to sponsor Let’s Encrypt please email us at sponsor@letsencrypt.org. We ask that you make an individual contribution if it is within your means.