How Let's Encrypt Runs CT Logs
Let’s Encrypt launched a Certificate Transparency (CT) log this past spring. We’re excited to share how we built it in hopes that others can learn from what we did. CT has quickly become an important piece of Internet security infrastructure, but unfortunately it’s not trivial to run a good log. The more the CT community can share about what has been done, the better the ecosystem will be.
Sectigo and Amazon Web Services have generously provided support to cover a significant portion of the cost of running our CT log. “Sectigo is proud to sponsor the Let’s Encrypt CT Log. We believe this initiative will provide much-needed reinforcement of the CT ecosystem,” said Ed Giaquinto, Sectigo’s CIO.
For more background information about CT and how it works, we recommend reading “How Certificate Transparency Works.”
If you have questions about any of what we’ve written here, feel free to ask on our community forums.
Objectives
- Scale: Let’s Encrypt issues over 1 million certificates per day, and that number grows each month. We want our log to consume our certificates as well as those from other CAs, so we need to be able to handle as many as 2 million or more certificates per day. To support this ever-increasing number of certificates, CT software and infrastructure need to be architected for scale.
- Stability and Compliance: We target 99% uptime, with no outage lasting longer than 24 hours, in compliance with the Chromium and Apple CT policies.
- Sharding: Best practice for a CT log is to break it into several temporal shards. For more information on temporal sharding, check out these blog posts.
- Low Maintenance: Staff time is expensive, we want to minimize the amount of time spent maintaining infrastructure.
System Architecture
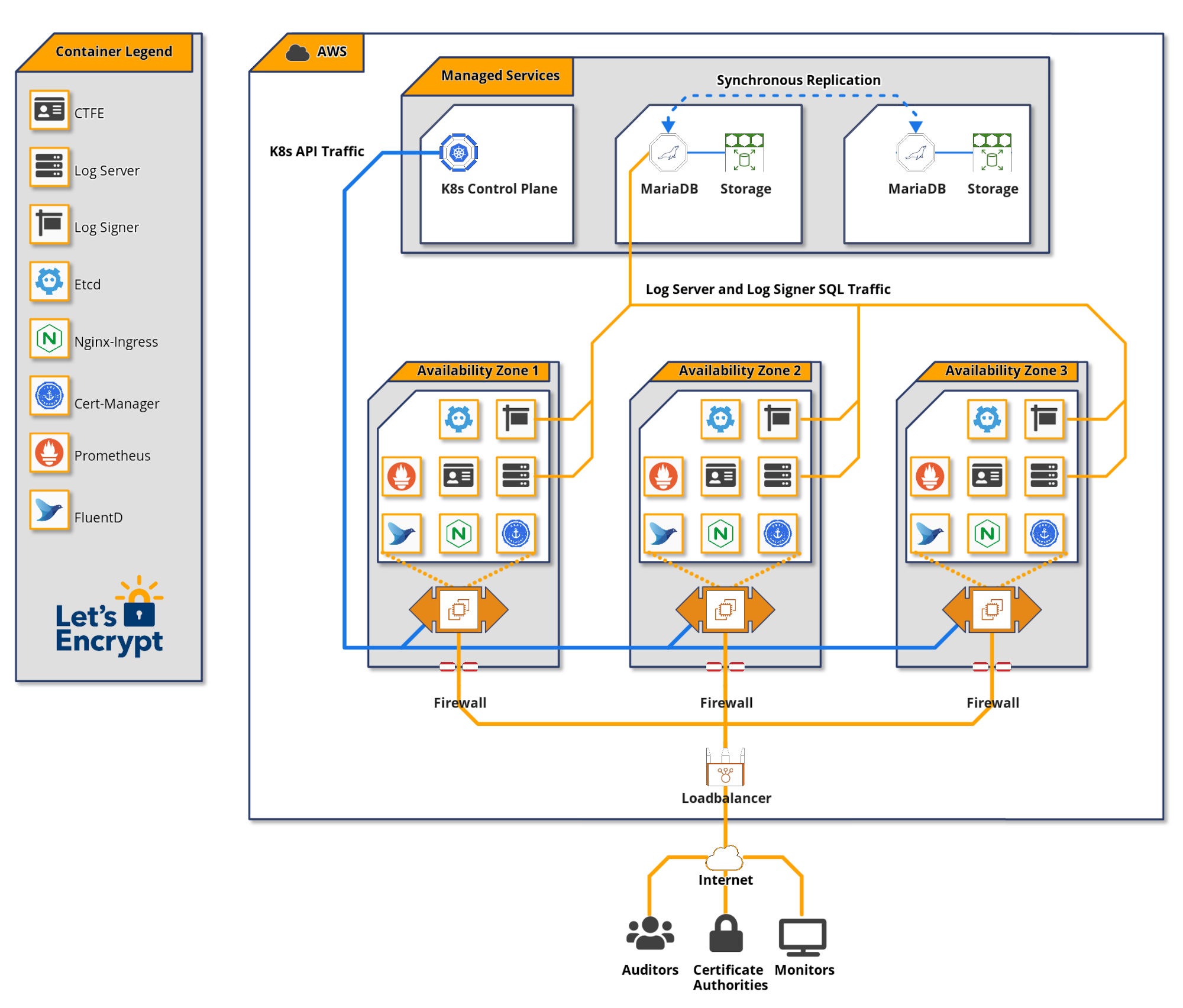
Staging and Production Logs
We run two equivalent logs, one for staging and one for production. Any changes we plan to make to the production log are first deployed to the staging log. This is critical for making sure that updates and upgrades don’t cause problems before being deployed to production. You can find access details for these logs in our documentation.
We keep the staging log continually under production-level load so that any scale-related problems manifest there first. We also use the staging CT log to submit certificates from our staging CA environment, and make it available for use by other CAs’ staging environments.
As a point of clarification, we consider a log to be comprised of several temporal shards. While each shard is technically a separate log, it makes sense to conceptualize the shards as belonging to a single log.
Amazon Web Services (AWS)
We decided to run our CT logs on AWS for two reasons.
One consideration for us was cloud provider diversity. Since there are relatively few trusted logs in the ecosystem, we don’t want multiple logs to go down due to a single cloud provider outage. At the time we made the decision there were logs running on Google and Digital Ocean infrastructure, as well as self-hosted. We were not aware of any on AWS (in hindsight we may have missed the fact that Digicert had started using AWS for logs). If you’re thinking about setting up a trusted log for CAs to use, please consider cloud provider diversity.
Additionally, AWS provides a solid set of features and our team has experience using it for other purposes. We had little doubt that AWS was up to the task.
Terraform
Let’s Encrypt uses Hashicorp Terraform for a number of cloud-based projects. We were able to bootstrap our CT log infrastructure by reusing our existing Terraform code. There are roughly 50 components in our CT deployments; including EC2, RDS, EKS, IAM, security groups, and routing. Centrally managing this code allows our small team to reproduce a CT infrastructure in any Amazon region of the globe, prevent configuration drift, and easily test infrastructure changes.
Database
We chose to use MariaDB for our CT log database because we have extensive experience using it to run our certificate authority. MariaDB has scaled well on our journey to becoming the largest publicly trusted certificate authority.
We chose to have our MariaDB instances managed by Amazon RDS because RDS provides synchronous writes to standby cluster members. This allows for automatic database failover and ensures database consistency. Synchronous writes to database replicas are essential for a CT log. One missed write during a database failover can mean a certificate was not included as promised, and could lead to the log being disqualified. Having RDS manage this for us reduces complexity and saves staff time. We are still responsible for managing the database performance, tuning, and monitoring.
It’s important to calculate the necessary amount of storage for a CT log database carefully. Too little storage can result in needing to undertake time-consuming and potentially risky storage migrations. Too much storage can result in unnecessarily high costs.
A back of the napkin storage estimation is 1TB per 100 million entries. We expect to need to store 1 billion certificates and precertificates per annual temporal shard, for which we would need 10TB. We considered having separate database storage per annual temporal shard, with approximately 10TB allocated to each, but that was cost prohibitive. We decided to create a 12TB storage block per log (10TB plus some breathing room), which is duplicated for redundancy by RDS. Each year we plan to freeze the previous year’s shard and move it to a less expensive serving infrastructure, reclaiming its storage for our live shards.
We use 2x db.r5.4xlarge instances for RDS for each CT log. Each of these instances contains 8 CPU cores and 128GB of RAM.
Kubernetes
After trying a few different strategies for managing application instances, we decided to use Kubernetes. There is a hefty learning curve for Kubernetes and the decision was not made lightly. This was our first project making use of Kubernetes, and part of the reason we went with it was to gain experience and possibly apply that knowledge to other parts of our infrastructure in the future.
Kubernetes provides abstractions for operators such as deployments, scaling, and service discovery that we would not have to build ourselves. We utilized the example Kubernetes deployment manifests in the Trillian repository to assist with our deployment.
A Kubernetes cluster is comprised of two main components: the control plane which handles the Kubernetes APIs, and worker nodes where containerized applications run. We chose to have Amazon EKS manage our Kubernetes control plane.
We use 4x c5.2xlarge EC2 instances for the worker node pool for each CT log. Each of these instances contains 8 CPU cores and 16GB of RAM.
Application Software
There are three main CT components that we run in a Kubernetes cluster.
The certificate transparency front end, or CTFE, provides RFC 6962 endpoints and translates them to gRPC API requests for the Trillian backend.
Trillian describes itself as a “transparent, highly scalable and cryptographically verifiable data store.” Essentially, Trillian implements a generalized verifiable data store via a Merkle tree that can be used as the back-end for a CT log via the CTFE. Trillian consists of two components; the log signer and log server. The log signer’s function is to periodically process incoming leaf data (certificates in the case of CT) and incorporate them into a Merkle tree. The log server retrieves objects from a Merkle tree in order to fulfill CT API monitoring requests.
{kind=link}
Load Balancing
Traffic enters the CT log through an Amazon ELB which is mapped to a Kubernetes Nginx ingress service. The ingress service balances traffic amongst multiple Nginx pods. The Nginx pods proxy traffic to the CTFE service which balance that traffic to CTFE pods.
We employ IP and user agent based rate limiting at this Nginx layer.
Logging and Monitoring
Trillian and the CTFE expose Prometheus metrics which we transform into monitoring dashboards and alerts. It is essential to set a Service Level Objective for the CT log endpoints above the 99% uptime dictated by CT policy to ensure that your log is trusted. A FluentD pod running in a DaemonSet ships logs to centralized storage for further analysis.
We developed a free and open source tool named ct-woodpecker that is used to monitor various aspects of log stability and correctness. This tool is an important part of how we ensure we’re meeting our service level objectives. Each ct-woodpecker instance runs externally from Amazon VPCs containing CT logs.
Future Efficiency Improvements
Here are some ways we may be able to improve the efficiency of our system in the future:
- Trillian stores a copy of each certificate chain, including many duplicate copies of the same intermediate certificates. Being able to de-duplicate these in Trillian would significantly reduce storage costs. We’re planning to look into whether this is possible and reasonable.
- See if we can successfully use a cheaper form of storage than IO1 block storage and provisioned IOPs.
- See if we can reduce the Kubernetes worker EC2 instance size or use fewer EC2 instances.
Support Let’s Encrypt
We depend on contributions from our community of users and supporters in order to provide our services. If your company or organization is interested in learning more about sponsorship, please email us at sponsor@letsencrypt.org. We ask that you make an individual contribution if it is within your means.